| トップ
| 植生調査
| 本の紹介
| リンク集
| 雑文
| Ruby
| R
| 自己紹介
|
e-mail adress
(Since on 2004-10-07)
(Updated on 2007-01-14)
統計解析ソフトRのページ
ここでは統計解析ソフトRで使用することのできる関数やプログラムの実行例を紹介します。ただし、中途半端な知識でやってますので、使用の際は自己責任でお願いします。また、間違いなどがあればぜひ教えてください。
統計解析ソフトRはRに関する本を、統計解析は統計解析に関する本を参考にしてください。
未完成ですが、植生学でデータ解析ソフト"R" を利用するその説明用の図(どちらもPDFファイル)も少しは参考になるかもしれません。
秀丸でRというマクロをしばらく前に作りました。秀丸エディタで使う際にいちいちコピーペーストするのが面倒な場合、マクロに登録してショートカットを登録しておけば Rterm で実行するというものです。
植生解析と関係の深いRのパッケージが2つあります。VEGAN(DCA/CCAなど)とLabDSV(Indicator Species Analysisなど)です。使い方は、Veganの説明書(PDF)・Veganの機能説明の教科書(説明書よりも具体的な使用方法が書かれている)とLabDSVの説明書(PDF)をご覧ください。
changelogのRのカテゴリにも小技やメモを追加しつつあります。
glmとモデル選択の実行例
TeXの表の出力で上下の線の幅を太くした関数
2つのデータフレームを共通の変数をキーにして結合する方法
applyの集計方法の関数で既定値以外のオプションを指定する方法
tapply関数でクロス集計する方法
使っていない要素を消す方法
テーブル形式のデータをデータフレーム形式のデータに変換する関数
集計した結果を見やすく表示する方法
棒グラフを書く関数(その1)
NAとNaNを0に変換する関数
NAを0として平均を計算する関数
正の数値を1に変換する関数
データフレームの情報を得る方法
2次元の行列でNAや0だけの行と列を除去する関数
共通して出現する種数を計算する関数
matplotを簡単に使えるようにした関数
2つのデータフレームでの片方に欠落する列を見つける関数
データフレーム内での重複行を見つける関数
一般化線形モデルでモデルをいくつか作って、それをモデル選択する関数
起動時に関数などを読み込む方法
植生調査データの解析準備するための一連の命令
点過程の計算例
調査結果から種数面積関係を計算する関数
分割表の無作為化検定(Randomization test)をする関数
ロジスティック回帰分析をする方法
複数の図を書く方法
因子オブジェクトに順位をつける方法
植生調査データの中から地点ごとの優占種を抽出する関数(その1)
関数を日本語化する方法
植生調査データの中から地点ごとの優占種を抽出する関数(その2)
植生調査データの中から地点ごとの優占種を抽出する関数(その3)
植生調査データの中から地点ごとの優占種を抽出する関数(その4)
subset で抽出したデータフレームの成分の存在していない level を消去する関数
連番をつける関数
ベクトルから対を作る関数
植生調査データの中から種・階層・被度でデータを抽出する関数
Gini Coefficient, Lorenz Curve, Lorenz Asymmetry Coefficient を計算する関数
Indicator Spcies Analysis を簡単に実行する関数
対応のある2変数の散布図とヒストグラムをxy座標で描画する関数
glmとモデル選択の実行例
第51回日本生態学会大会 (釧路) の自由集会での北海道大学の久保さんの話題提供のPDFファイルを見ながら実行してください。
TeXの表の出力で上下の線の幅を太くした関数
ちょっといじっただけなので、全体については良く分かっていません。とりあえず使えるとは思いますが…。
2つのデータフレームを共通の変数をキーにして結合する方法(具体例)
調査地点のデータ(例えば、地点名と都道府県名)と調査自体のデータ(例えば、地点名と種名)を別々のデータフレームとして保存しているとする。都道府県ごとでの出現種を見たい場合にはデータフレームを結合する必要がある。そういったことをするには、merge関数を使うと良い。あらかじめデータの変数を同じ物にしておくと自動的に結合してくれる。
applyの集計方法の関数で既定値以外のオプションを指定する方法(例示)
applyは行あるいは列のデータを集計するときに使う関数である。ただし、欠損値のあるデータで平均値を計算すると「NA」が帰ってきて、うまく結果が出ない。こんな場合には、集計方法の指定の後ろに、オプションの引数を指定する。その他のオプションも同じように指定すればいいはず。
tapply関数とapply関数でクロス集計する方法(例示)
tapplyは項目別の項目を集計する関数である。上記のapply関数と一緒に使うと、さらに高度な集計(エクセルのピボットテーブルのようなもの)ができる。
使っていない要素を消す方法
データフレームからsubset関数を使って、データを取り出しても、使われていない要素名が名前だけ残っている。この残った要素名が厄介者で、集計をすると使われていない要素名がまたでてくる。そういった使われていない要素を消す方法は、以下のとおり。どちらも同じ働きをする。
要素名 <- 要素名[,drop = TRUE]
要素名 <- factor(要素名)
テーブル形式のデータをデータフレーム形式のデータに変換する関数
植生調査などの組成表形式のデータを一気にデータベース形式のデータに変換する。オプションの指定によって、値が0のデータを含めることも可能。ただし、この関数は自分で作った初めての関数なので、非常にきたない形です。さらに、2回目の車輪かも。
追記:わざわざこの関数を使わなくても、as.data.frame.tableという関数で変換可能であることが後で判明した。
追記2:as.data.frame.tableはdata.frameからdata.frameへは変換できない。matrixからdata.frameに変換するようである。
集計した結果を見やすく表示する方法
tapplyやapplyを使った集計で区分の項目が2つの場合は、縦横の2次元のテーブルで普通に理解できる表示がされる。しかし、項目が3つ以上になると3つ目の区分ごとに分割された形で見にくい表示になってしまう。こんなときは、ftableを使うと分かりやすい形で表示してくれる。
ftable(tapply(集計対象, list(集計項目1, 集計項目2, 集計項目3), 関数))
棒グラフを書く関数(その1)
barplotという関数で簡単な棒グラフを書くことができるが、データフレームから直接は棒グラフを書くことはできない。ちょっと拡張して使いやすくした。凡例も含めて書いてくれる。一から作ったのではなくて、RjpWikiのグラフィックス参考実例集:棒グラフにあるものを改変した。
NAとNaNを0に変換する関数
いろいろな計算をするときに、データフレームや行列内のNAとNaNが邪魔になることがある。これらを0に変換する関数を作った。
NAを0として平均を計算する関数
mean(x, na.rm=TRUE)とするとNAのデータは無視されて、他のデータのみの平均値を求めることができる。ただ、NAを0と同じ扱いにすることはできないので、ちょっとした関数を作った。
正の数値を1に変換する関数
植生データなどでは、量的なデータだけでなく、有無データ(1か0か)というのを使うことが時々ある。そんなときのための関数を作った。ついでにNAを0に変換するようにした(オプションでNAのままも可能)。ただし、数値以外(因子や文字列など)がデータに入っているものを変換すると、1として出力されてしまうので注意が必要。
データフレームの情報を得る方法
データフレームの内容・要約・列名・行名・列数・行数などを得る方法です。
2次元の行列でNAや0だけの行と列を除去する関数
植生データなどでデータを抽出した場合に不要なデータがたくさんくっついてくることがある。それを除去するための関数です。ただし、行列に名前がついていない場合はうまく動かない。
共通して出現する種数を計算する関数
植生データなどで出現種と地点名とを行と列とに並べて、本数や被度などの値をデータとしていることがよくある(植物社会学での組成表など)。そのデータから地点ごとの共通種数を計算する関数です。入力データは、行に地点名、列に種名を並べたものにしておく。普通の組成表とは逆なので、組成表を使って計算するときは、t()関数によって行列の入れ替えをしておく必要がある。
matplotを簡単に使えるようにした関数など
3列からなるデータフレームや行列で、第1列をx軸に配列したいデータ、第2列をy軸に配列したいデータ、第3列を区分する項目とすれば簡単にmatplotができるようにした。
また、matplotのような働きをする関数(matplotもどき)も作った。
2つのデータフレームでの片方に欠落する列を見つける関数
共通する項目(列の名前が同じ)を持つデータフレームで、その値がどちらかだけにあるものをそれぞれ抽出する。
データフレーム内での重複行を見つける関数
データフレームの中で待ったく同じ値を持つ行を抽出する。
一般化線形モデルでモデルをいくつか作って、それをモデル選択する関数
ポワソン分布とガウス分布(正規分布)でのモデル選択(北海道大学の久保さん作成のpdfファイル)をする。ほとんどオリジナル部分はなくて、北海道大学の久保さんが作成された関数がほとんどである。
起動時に関数などを読み込む方法
「.Rprofile」というファイルをRの実行ファイルと同じフォルダにおいておく。ファイルの中身に関数そのものを書いておいても良いし、「source("d:/hoge/hoge.r")」として、関数を入れているファイルを指定しても良い。
植生調査データの解析準備するための一連の命令
用意した組成データ(例)・地点データ(例)・種データ(例)・異名データ(例)をまとめて、基礎データ(階層なし(例)/付き(例))・組成表(階層なし(例)/付き(例))を作成する一連の命令です。
点過程の計算例
ライブラリspatstatを使ったpair correlation・K関数・L関数の計算とグラフの作成の例を示す。データはライブラリに含まれているサンプルデータを使ったもの。データはマークつきのものも含む。点過程について詳しいことは日本生態学会誌の論文(島谷健一郎.2001.点過程による樹木分布地図の解析とモデリング.日本生態学会誌,51,87-106)と国立環境研究所の竹中さんのページにある点過程解析用プログラムに書かれている。
調査結果から種数面積関係を計算する関数
実際の植生調査結果を利用して、その中から無作為に調査地点を選んでいったときの種数面積関係を計算する。反復回数を多くして種数面積曲線を描けば、データの持っている特性がわかる。調査地点の面積が異なっている場合は、調査面積のデータを入力することで対応するようにしている。
分割表の無作為化検定(Randomization test)をする関数
分割表の無作為化検定(Randomization test)をする関数(その2)
n×nの分割表で、行列の合計を固定したまま分割表の乱数を作成して、入力したデータの発生確率を計算します。既定値では10000回の反復をしますので、出力結果が0の場合は1/10000未満(0.01%未満)ということです。2つ目の方では r2dtable() という関数を使って関数の定義を短くしています。動作も少し速いような気がします。
ロジスティック回帰分析をする方法(例示)
独立変数として環境傾度などの連続量、従属変数としてある種の出現の有無を想定した場合での、その種の環境傾度沿いでの出現確率を推定する方法です。
複数の図を書く方法(例示)
x軸とy軸を複数の図で共用する場合で、複数の図を1枚の図として出力する方法です。左端と最下の図にのみ、軸の説明を入れるようにしています。
因子オブジェクトに順位をつける方法(例示)
植生の階層構造などのように順序尺度のあるデータをつくる方法です。
植生調査データの中から地点ごとの優占種を抽出する関数(その1)
layerに階層・coverに被度・speciesに種・standに地点のデータが入ったデータフレームを与えると、最上層にある種で閾値を越える被度を持つものを優占種として、地点・優占種・最上層の階層・優占種数を返します。閾値の初期値は0.24ですが、変更可能です。階層名は、b1,b2,s1,s2,k1,k2(高木層,亜高木層,第一低木層,第二低木層,第一草本層,第二草本層)を使わなければなりません。
関数を日本語化する方法
日本語化されたRならば、もともと英語(アルファベット)で表記されている関数を日本語に置き換えてやれば、一応日本語化ができる。ただし、やったとしても、利点はさほど大きくない。例えば、「merge」という関数を「合併」という関数に変えるには、次のようにする。
合併 <- function(x, y, by = intersect(names(x), names(y)),by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all,sort = TRUE, suffixes = c(".x",".y"), ...){merge(x, y, by = intersect(names(x), names(y)),by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all,sort = TRUE, suffixes = c(".x",".y"), ...)}
植生調査データの中から地点ごとの優占種を抽出する関数(その2)
layerに階層・coverに被度・speciesに種・standに地点のデータが入ったデータフレームを与えると、最上層にある種で最大被度をもつものを優占種として、地点・優占種・最上層の階層・優占種数・優占種の被度を返します。階層名は、b1,b2,s1,s2,k1,k2(高木層,亜高木層,第一低木層,第二低木層,第一草本層,第二草本層)を使わなければなりません。その1との違いは、一定の被度以上のものを優占種とするのではなく、最大被度のものを優占種とする点です。
植生調査データの中から地点ごとの優占種を抽出する関数(その4)
基本は
その1と同じですが、複数種が優占する場合の出力方法が異なります。
植生調査データの中から地点ごとの優占種を抽出する関数(その4)
基本はその2と同じですが、複数種が優占する場合の出力方法が異なります。
subset で抽出したデータフレームの成分の存在していない level を消去する関数
subset を使うと、条件にあったデータだけの抽出を簡単にできます(特定の群落・特定の地点・特定の種など)。ただし、不要な要素が残ってしまうのが欠点です。lapply + factor を使えば不要な要素を除去可能です。でも、数値が要素に変換されたりと不都合があります。そこで、要素にあたるものだけに対して factor を適用する関数を作りました。また、subset と組み合わせることで、subset + 不要な要素の除去を一気にやってしまう関数も作りました。
連番をつける関数
地域名や群落名が同じ地点に対して、区分を分かりやすくするために、地域名や群落名をに連番をつけます。具体的には「コナラ、コナラ、アカマツ、コナラ、アカマツ」というのに対して、「コナラ1、コナラ2、アカマツ1、コナラ3、アカマツ2」という連番をつけます。さらに、並べ替えのときに作業しやすいように、桁数が多い場合は桁数にあわせて連番を「01,02・・・10,11」にします。
ベクトルから対を作る関数
「G1,G2,G3,G4」というベクトルから「G1-G2,G1-G3,G1-G4,G2-G3,…」という対を作ります。オプションで「G1-G2,G2-G1」という重複の組み合わせを作るかどうかを選択できます。
植生調査データの中から種・階層・被度でデータを抽出する関数
種名・階層・被度を指定して、それを含む地点のデータを抽出します。例えば、「b1層にコナラが被度20以上出現している地点のデータ」という具合です。rm.level()という関数を使っているので、別途登録してください。出力したデータフレームの成分に不要な要素が入っていてもよければ、最終行は削除してください。
Gini Coefficient, Lorenz Curve, Lorenz Asymmetry Coefficient を計算する関数
DESCRIBING INEQUALITY IN PLANT SIZE OR FECUNDITYという論文にあるGini Coefficient
とLorenz CurveとGini Asymmetry Coefficientを計算します。群馬大の青木さんが既にローレンツ曲線を描いてジニ係数を求める関数を作っておられるものの、Gini Asymmetry Coefficient は出力されません。
Indicator Spcies Analysis を簡単に実行する関数
Indicator Spcies Analysisは独立したプログラムとしてDOSのコマンドライン上から実行できます。ただし、入力データを整理・DOS窓での入力・解析結果の整理をしなければならず、手間がかかります。Rのパッケージ labdsv の duleg() という関数で実行可能なため、DOSプログラムよりは使いやすくなったのですが、より使いやすく(少なくとも自分にとって)するために関数を作りました。stand, species, cover, community という成分を持つデータフレームを入力すれば、community ごとに indicator species, indicator value, p value を出力します。
註:時々、原因不明でRが固まってしまうことがあります。
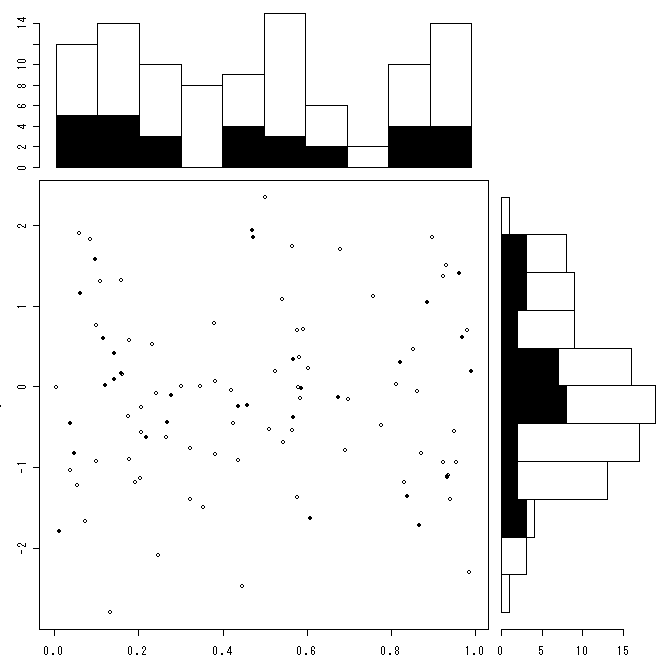
対応のある2変数の散布図とヒストグラムをxy座標で描画する関数
RjpWikiのグラフィックス参考実例集を参考にして対応のある2変数のxy散布図とその横と上にヒストグラムを描画する関数です。さらに、そのうちの特定のものの散布図とヒストグラムを塗りつぶす関数も作りました。言葉では表現しづらいので、作図例1・作図例2を見てください。
Rの参考リンク集:Rを使う上で参考になるページたち
Rヘルプの日本語訳
グラフィックス参考実例集(RjpWiki)
RプログラミングTips大全(RjpWiki)
Rノート:データ解析とグラフィックスのためのプログラミング環境(pdf)
統計解析ソフトRの備忘録(pdf)
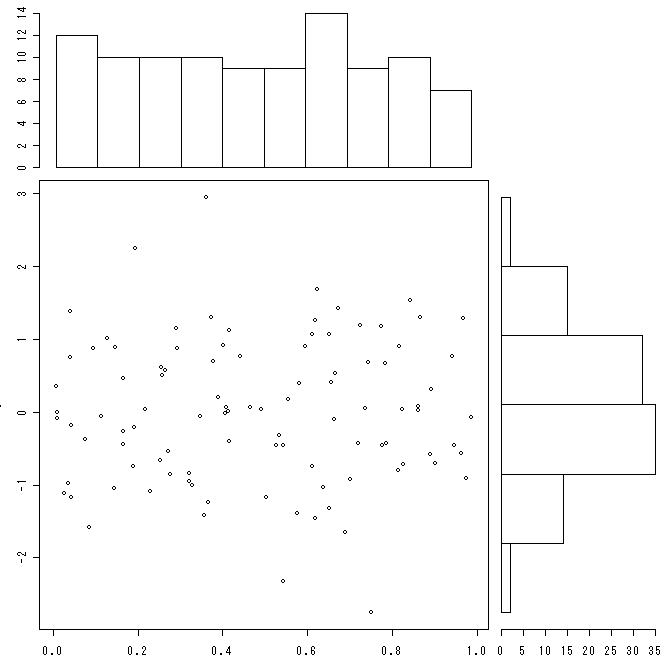{kind=link}
{kind=link}