松村俊和のページ:日記 / 2007-02
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
2008 : 01 02 03 04 05 06 07 08 09 10 11 12
2007 : 01 02 03 04 05 06 07 08 09 10 11 12
2006 : 01 02 03 04 05 06 07 08 09 10 11 12
2007-02-03
修正作業[diary]
2006-12-17に投稿した論文が2007-01-25に校閲作業を受けて帰ってきた.先々週と先週は仕事が忙しかったためほとんど修正作業ができなかった.作業前はすぐに終わると思っていたが,いざやりはじめると結構時間がかかる.個別箇所の修正だけですめば楽だが,他の部分に関係するところだと全体の整合性を考えて修正しなければならないためだ.今週末で終わるだろうか.なんとか終えたい.
2007-02-06
顔パス[diary]
ウィンドウズPCに「顔」でログインできるというシステム.登録された人の写真をカメラの前においたらどうなるのだろうか?写真のように(並行移動以外で)全く画像が動かないというのは通常の顔では考えられないので,そんな場合はログインできないとかというようになっているのだろうか?それとも声と合わせて認識させるとか.
2007-02-07
迷惑メール内でのストップ語検索[google]
メールアドレスとして,Gmailと前から使っているGmail以外のものを併用している.このGmail以外のプロパイダを通ってくる迷惑メールは,題名のはじめに[spam]というのがついてきて,Gmailでは迷惑メールに分類される.ただ,この[spam]付というのが非常に多くて一日に何十通とくる.通常のメールがGmailで誤分類されてしまうとこの[spam]というメールに埋もれてしまう.そんなときは,Gmailの検索で,「in:spam -[spam]」というのを検索すると,埋もれてしまったものを抽出できる.そうすることで,頻繁に確認しなくても,かなり低い頻度で確認しても大丈夫だ.
ということを昨日気づいた.
参考:「in:spam」という部分は迷惑メールのフォルダの中,「-[spam]」というのが[spam]を含まない(「-」が含まないということ)
2007-02-08
ヨンクヒール[stat][r]
先日,BIOMETRY:生物統計学メーリングリストの投稿でヨンクヒール(Jonckheere)の検定というのが書かれていた.クラスカル・ウォリス検定ににているが,多数のぐんのうちどれかが違うかというのではなくて,傾向性を検定するようだ.
参考:傾向検定
Rで実行:http://aoki2.si.gunma-u.ac.jp/R/Jonckheere.html
2007-02-09
テキスト比較[tool][論文]
論文を書いていると,いろいろな場面でいろいろな人から指摘や助言を受けて原稿を修正することがある.
修正のたびにいちいちメモするのは面倒だし,最後に修正前の原稿と修正後の原稿でどこが違うのかを目で見比べるのは面倒かつ,見落としがでてくる.そんなときは,テキスト比較の道具を使うのが良い.
一般的なワープロソフトのMSワードは[ツール]-[変更履歴の作成]で変更履歴を残したり,[ツール]-[変更履歴の作製]-[文書の比較]で一応文書を比較できる.
2007-02-11
TeXの本[tex][book]
TeX関連で気になる本が2冊.
一歩踏み込むLATEXの基本
TeXのコマンドを解説しているページ[tex]
以下は項目ごとにページが分かれている
2007-02-12
パソコンの電源ボタン[diary]
パソコンの電源ボタンが壊れてしまった.2-3日前からボタンが妙に傾いているとは感じていた.それが,今日になって完全に取れてしまった.どうも,必要以上にボタンを強く押す癖があるようだ.同じ型のパソコンがあるので,試しにそれを押してみると,果たして強く押していた.そういえば,前の職場のパソコンの電源ボタンも壊したことがあった.
2007-02-13
ワードで行番号を表示させる[diary][tool][論文]
編集箇所を示すときに,行番号があると便利.今まで全然使っていなかった.設定場所が分かりにくいので,覚え書き.
設定場所:[メニュー]-[ファイル]-[ページ設定]-[行番号]-[行番号を追加する]
参考:http://www.relief.jp/itnote/archives/001015.php
2007-02-14
「比が同じ」か「差が同じ」か?[stat]
自分が普段扱っている資料は,差が同じかどうか?ということを気にかけているが,比が同じか?ということはあまり考えていない.時々は,考えてみる必要があるかも.馬車馬のように: [統計]比(割合)が一定と交互作用とを読んでそう思った.
2007-02-19
Ecography OnlineEarly Articles[article]
Plant Ecology 189 1[article]
Journal of Ecology 95 2[article]
Conservation Biology 21 1[article]
2007-02-20
ウェブでコーパス分析[tool][english]
[2006-03-17]に書いたコーパス分析をCobuild Concordance and Collocations Samplerというページでできるらしい.
使い方
単語を繋げる時は「+」で繋ぐ
例:in+relation
単語の間に別の単語がある場合も入れる
例:has+been+3recognized
例:from+3to
単語の活用を含める
例:show@
例:wide@
ワイルドカード「*」
例:wide*
単語のどれか「|」
例:relation|relationship
品詞を指定(単語の後ろに「/NOUN」というふうに)
例:form/NOUN
NOUN: a macro tag: stands for any noun tag
VERB: a macro tag: stands for any verb tag
NN: common noun
NNS: noun plural
JJ: adjective
DT: definite and indefinite article
IN: preposition
RB: adverb
VB: base-form verb
VBN: past participle verb
VBG: -ing form verb
VBD: past tense verb
CC: coordinating conjunction (e.g. "and" or "but")
CS: subordinating conjunction (e.g. "while", "because")
PPS: personal pronoun subject case (e.g. "she", "I")
PPO: personal pronoun object case (e.g. "her", "me")
PPP: possessive pronoun (e.g. "hers", "mine")
DTG: determiner-pronoun ("many", "all", "both", "some" etc.)
Referrer (Inside):
[2007-05-16-1]
2007-02-21
Global Ecology and Biogeography OnlineEarly Articles[article]
レズリー行列の計算例[stat][r]
必要があって,個体群生態学の基本を勉強している.『動物生態学』
## レズリー行列を作る関数
make.reslie <- function(recruit, survive){ # (recruit:齢別出生数 survive:齢別期間生存率)
i <- length(recruit)
reslie <- matrix(0, nrow=i, ncol=i) # 0行列
reslie[1,] <- recruit # 齢別出生数
for(j in 1:(i-1)){ # 齢別期間生存率
reslie[j+1, j] <- survive[j]
}
reslie
}
## レズリー行列と初期値から個体群の動態を計算する
pop.dynamic <- function(reslie, initial, n=20){ # reslie:レズリー行列 initial:初期値 n:世代数
i <- ncol(reslie)
pop.dyn <- initial # 1世代目
pop <- reslie %*% initial # 2世代目
pop.dyn <- cbind(pop.dyn, pop)
for(j in 3:n){
pop <- reslie %*% pop # 3世代目以降
pop.dyn <- cbind(pop.dyn, pop)
}
pop.dyn
}
## 個体群の動態を散布図にする
plot.dynamic <- function(dy){
n <- ncol(dy) # 世代数
m <- nrow(dy) # 齢数
plot(dy[1,], type="b", log="y", ylim=c(min(dy),max(dy[1,]))) # 最小齢の動態の散布図
for(i in 2:m){ # 各齢の動態の散布図
par(new=T)
plot(dy[i,], type="b", log="y", ylim=c(min(dy),max(dy[1,])))
}
}
## レズリー行列と初期値から平衡に達するまでの動態を計算する
pop.equil <- function(reslie, initial, n=5){ # reslie:レズリー行列 initial:初期値 n:平衡後の世代数
i <- ncol(reslie)
pop.dyn <- initial # 1世代目
pop <- reslie %*% initial # 2世代目
pop.dyn <- cbind(pop.dyn, pop)
j <- 2 # 第2世代から開始
ratio.befor <- round(pop.dyn[,j-1] / sum(pop.dyn[,j-1]), 5) # 第1世代の頻度分布
ratio.after <- round(pop.dyn[,j] / sum(pop.dyn[,j]), 5) # 第2に世代の頻度分布
while(sum(ratio.befor!=ratio.after)>0){
pop <- reslie %*% pop # 3世代目以降
pop.dyn <- cbind(pop.dyn, pop)
ratio.befor <- round(pop.dyn[,j] / sum(pop.dyn[,j]), 5)
ratio.after <- round(pop.dyn[,j+1] / sum(pop.dyn[,j+1]), 5)
j <- j + 1 # 次の世代へ
}
for(k in 1:n){ # 平衡後n世代を計算
pop <- reslie %*% pop # 3世代目以降
pop.dyn <- cbind(pop.dyn, pop)
}
list(dynamics=pop.dyn, ramda = sum(pop.dyn[,j+n])/sum(pop.dyn[,j+n-1]))
}
## 基礎情報の設定
recruit <- c(0, 2, 3, 4, 1) # 齢別出生数
survive <- c(0.4, 0.7, 0.7, 0.7, 0) # 齢別期間生存率
initial <- c(10, 2, 2, 2, 2) # 初期値
initial2 <- c(1, 5, 1, 1, 1) # 初期値
## 計算・作図
reslie <- make.reslie(recruit, survive) # レズリー行列
dy <- pop.dynamic(reslie, initial, 15) # 個体群動態を計算
par(mfrow=c(1,3))
plot.dynamic(dy) # 個体群の動態から散布図を作図
dy2 <- pop.dynamic(reslie, initial2, 15)
plot.dynamic(dy2)
dy3 <- pop.equil(reslie, initial, n=10) # 平衡に達するまでを計算
plot.dynamic(dy3$dyn)
dy3 # 平衡に達するまでの動態と固有値(λ)
2007-02-23
Rのグラフィクスの余白設定[r]
The R tipsを見たりそのウェブ版のRのグラフィクスの余白設定を参考にするが,いつもすぐに忘れてしまうので,覚え書きの例.
pdf("d:/tmp.pdf")
layout.show()
par(omi=c(1,1,0.5,0.5)) # 全体の余白を下左上右の順で指定
layout.show()
lay <- layout(matrix(c(1,2), nrow=2)) # 縦2横1に画面分割
layout.show(lay)
par(mai=c(0.1, 0.1, 0.1, 0.1)) # 個々の余白を下左上右の順で指定
plot(sin, -pi, 2 * pi)
par(mai=c(0.5, 0.5, 0.5, 0.5)) # 個々の余白を下左上右の順で指定
plot(cos, -pi, 2 * pi)
dev.off()
2007-02-24
行列の資料をヒストグラムに[stat][r]
行列をヒストグラムみたいなもので,表現する関数(作図例).
## 行列資料で行ごとの数値をヒストグラム(もどき)で表示する
mat.hist <- function(mat, omi=rep(0.5, 4), mai=rep(0, 4), ratio=NA, ...){ # 行列と余白の設定
if(is.na(ratio)) ratio <- sapply(as.data.frame(t(mat)), max) # 各行の最大値(グラフの割合)
n <- nrow(mat) # 列数
layout(matrix(1:n, nrow=n), heights=ratio, TRUE) # 作図画面を分割
par(omi=omi) # 全体の余白
par(mai=mai) # 個々の余白
for(i in 1:n){ #
barplot(mat[i,], axes=FALSE, space=0, ...) # ヒストグラム(みたいなもの)
axis(side=2, ...) # 個々のグラフのy軸
}
axis(side=1) # 全体のx軸
}
# 使用例
m <- matrix(abs(rnorm(100)), ncol=20) # 乱数を発生
mat.hist(m) # 図示
画像の切り抜き[tool]
それほど使用頻度は高くないが,画像を綺麗に切り抜くのは難しいし,神経を使う作業だ.それが簡単にできるのならうれしい.
画像内の対象物を簡単かつ綺麗に切り抜けるレタッチソフト「鋏」
Referrer (Inside):
[2007-03-09-1]
2007-02-25
Restoration Ecology 15 1[article]
Agriculture, Ecosystems & Environment 120 2-4[article]
spatstat のいろいろな機能[stat][r]
忘れたときのためのメモ.密度分布・距離分布・最も近い点・透視図・解析の要約表示など.
参考:Journal of Statistical Softwareに掲載されたマニュアル.
library(spatstat) # ライブラリの呼び出し
data(cells) # データの呼び出し
# 密度分布図
par(mfrow=c(2,2)) # 2*2に分割
for(i in seq(from=0.07, to=0.08, by=0.01)){
Z <- density.ppp(cells, i) # 密度の推定
plot(Z, main = "Kernel smoothed intensity") # 密度分布
plot(cells, add = TRUE) # 散布図を追加
}
# 距離分布
Z <- distmap(cells, dimyx = 512)
plot(cells$window, main = "Distance map")
plot(Z, add = TRUE)
points(cells)
# 最も近い点を探す
plot(cells) # 散布図
m <- nnwhich(cells) # 最も近い点を探す
b <- cells[m] # 最も近い点との対応を作る
arrows(cells$x, cells$y, b$x, b$y, angle = 12, length = 0.1, col = "red") # 矢印で表示
# 透視図
persp(Z, colmap=terrain.colors(128), shade=0.3, phi=45, theta=30, main="perspective plot")
# 各種解析の要約表示
plot(allstats(cells)) # for unmarked point pattern
指標付点過程(マーク付点過程:marked point pattern)[stat][r]
点過程のライブラリ spatstat の関数一覧.
マーク付点過程の解析方法を調べていたが,ネットで探してみると自分のRのページ紹介していたのがわかった.
# その他使えそうな関数の一覧
library(spatstat) # ライブラリの呼び出し
unmark # 指標を取り除く
setmarks # 指標を付ける
%mark% # 指標を付ける
cut # 指標の操作
split # 指標の操作
cut.ppp # 数値の指標を因子(factor)の指標に変換
split.ppp # 指標の因子ごとに分割
superimpose # 点過程を統合
nndist # nearest neighbour distance
pairdist # distance between each pair of points
Gcross # Multitype Nearest Neighbour Distance Function (i-to-j)
Gdot # Multitype Nearest Neighbour Distance Function (i-to-any)
Gest # Nearest Neighbour Distance Function G
Gmulti # Marked Nearest Neighbour Distance Function
Jcross # Multitype J Function(i-to-j)
Jdot # Multitype J Function(i-to-any)
Jest # Estimatethe J-function
Jmulti # Marked J Function
Kcross # Multitype K Function (Cross-type)
Kdot # Multitype K Function (i-to-any)
kest # K-function
Kmulti # Marked K-Function
 トゲクロザコエビ
トゲクロザコエビ トゲクロザコエビの刺身
トゲクロザコエビの刺身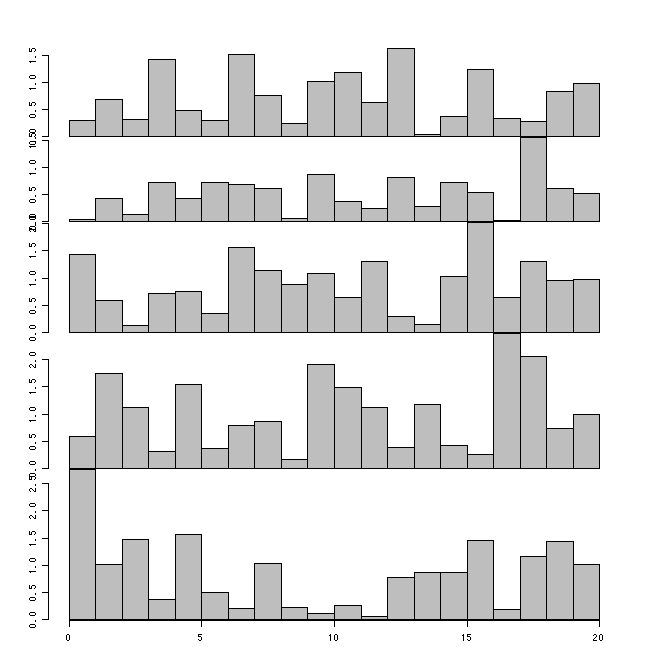{kind=link}
2009 : 01 02 03 04 05 06 07 08 09 10 11 12
2008 : 01 02 03 04 05 06 07 08 09 10 11 12
2007 : 01 02 03 04 05 06 07 08 09 10 11 12
2006 : 01 02 03 04 05 06 07 08 09 10 11 12
最終更新時間: 2009-12-01 22:42